Using Azure ADF to orchestrate dbt on Azure Databricks does not come ‘out of the box’. But with a little setup and the proper configuration dbt commands can be incorporated into any ADF pipeline.
If you are reading this post, you are probably already familiar with what dbt, Microsoft Azure, Azure Data Factory (ADF) and Databricks are.
Below is a brief description of the technologies we will be using.
dbt (data build tool) – by dbt Labs
dbt an open-source software created by “dbt Labs”. dbt’s “core” functionality is open source and free for use by its growing fan base. As a corporate offering, dbt Labs offers a paid subscription service adding additional functionality including a job scheduler, GIT integration, AIM and more. If you are not familiar with dbt Labs as a company, we urge you to check them out at https://www.getdbt.com/
Azure Data Factory – ADF – by Microsoft
Azure Data Factory is an orchestration tool that comes as part of the Microsoft Azure platform. It is a fully functional ETL tool (extract, transform, load) and it comes with connectors for almost any platform. It allows for the creation, scheduling and monitoring of data pipelines and it’s a key component for many Azure customers.
Azure Databricks – by Microsoft & Databricks
Azure Databricks is the Microsoft flavor of Databricks. Databricks is a “Big Data” platform that allows for parallel computing in a variety of languages (Python. Scala, R, Java, SQL). In recent releases Databricks has added functionality that includes a “SQL Database” (similar to Snowflake in storage architecture), Delta Tables – allowing ACID Transactions, and Delta Live Table which offers engineers the ability to build and schedule pipelines.
How to execute dbt commands on Azure Databricks as part of an Azure Data Factory (ADF) pipeline
Environment – Prerequisites / Requirements
Azure Setup
An Azure Storage Account must exist
An Azure Databricks workspace has been set up
Azure Databricks compute has python libraries azure-storage-file and dbt-databricks installed
An Azure Databricks token is available to connect Azure ADF –> Azure Databricks
An Azure Databricks SQL Endpoint has been created
An Azure Data Factory (ADF) exists to trigger a dbt run
dbt Setup
dbt-databricks has been pip installed on your local machine
A dbt project has been created and “init” has been run – to connect to the Databricks SQL endpoint
A sample dbt model or other artifacts have been created in your dbt project
The dbt project passes “debug” tests
The dbt project has been checked into your favorite GIT repository and merged into the “main” branch
Your dbt profiles.yml file (usually found in your .dbt folder) has been added to GIT or is available to manually upload to Azure Blob Storage
Steps for connecting Azure ADF to Azure Databricks and executing a dbt command
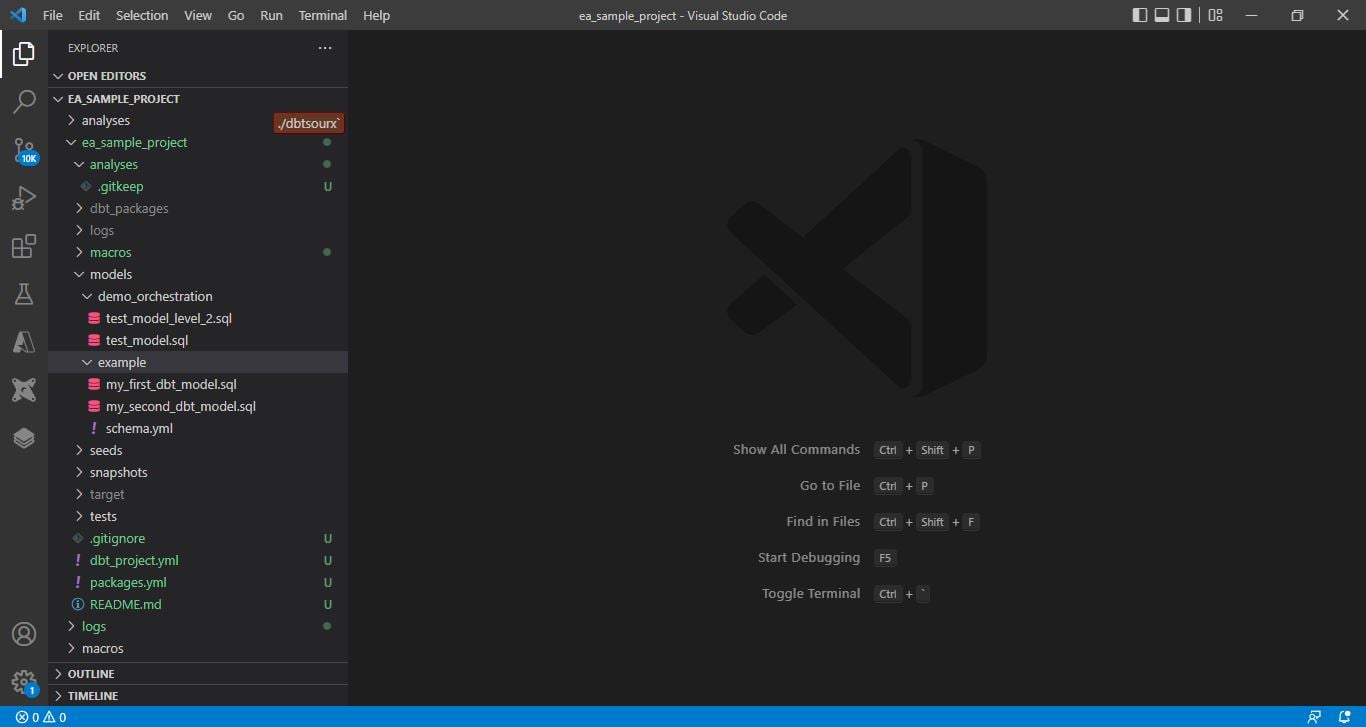
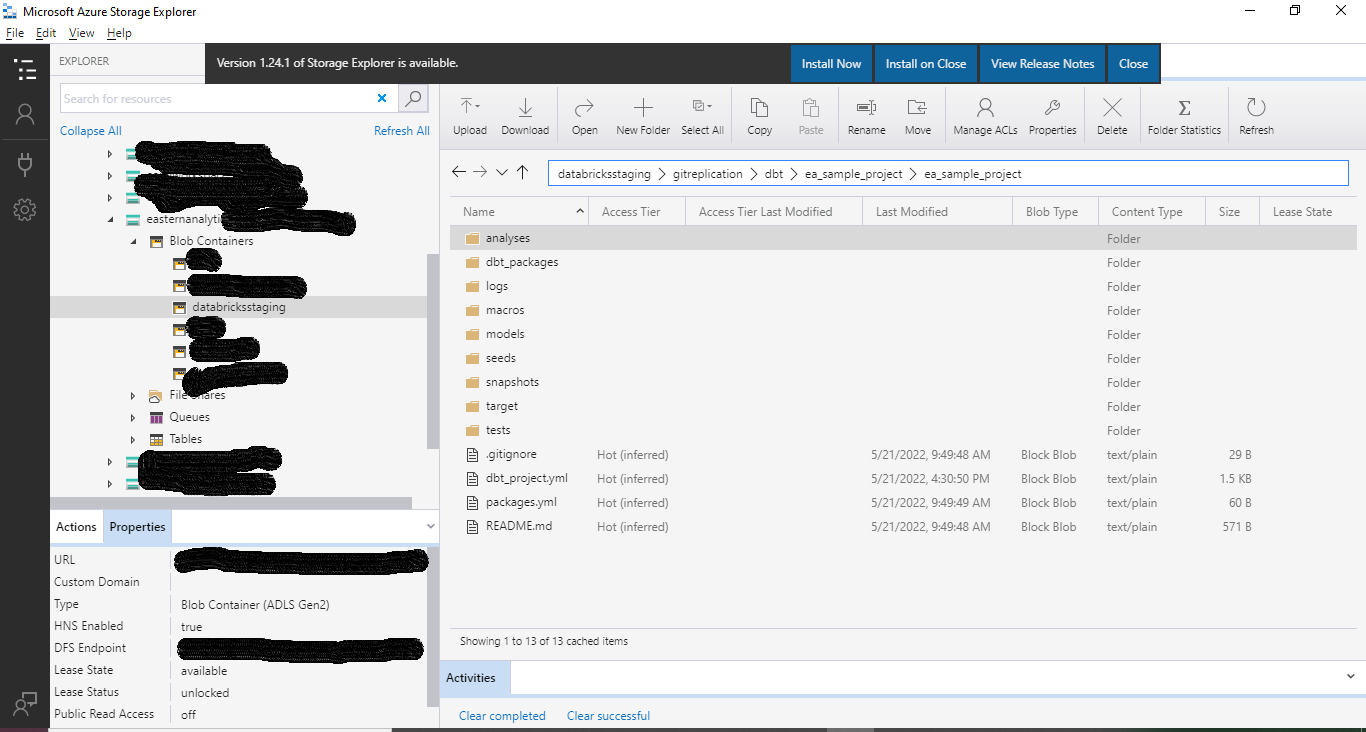
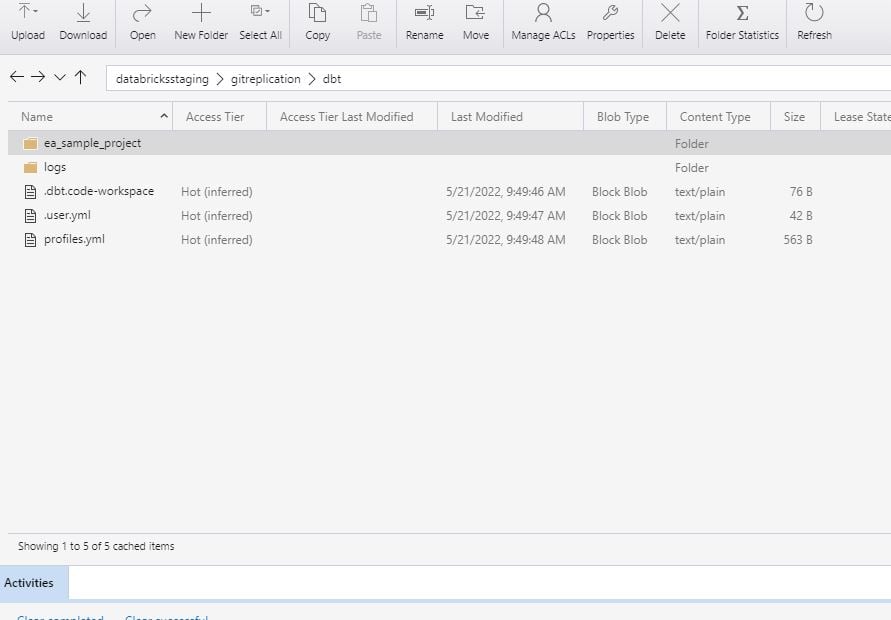
1) Upload your dbt project files to an Azure Blob Storage location. The top image is a dbt project viewed within an IDE, the bottom image is of the same project uploaded to Azure Blob Storage. Note: In the last step we will suggest a GitHub Action keep the blob files in sync with your Main branch every time yo you publish.
2) Upload your dbt profile.yml file to an Azure Blob Storage location. This file stores the connection information dbt will use when executing its commands on Azure Databricks (in this case, the Databricks compute will use a SQL endpoint created in the same Databricks workspace to execute its commands!).
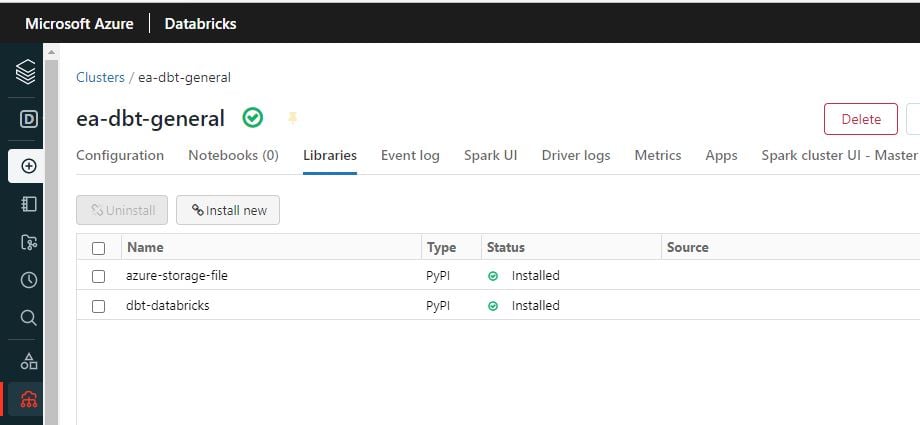
3) Install the dbt and Azure libraries on your Databricks compute cluster – these allow you to access your Azure blob storage and executing your dbt commands.
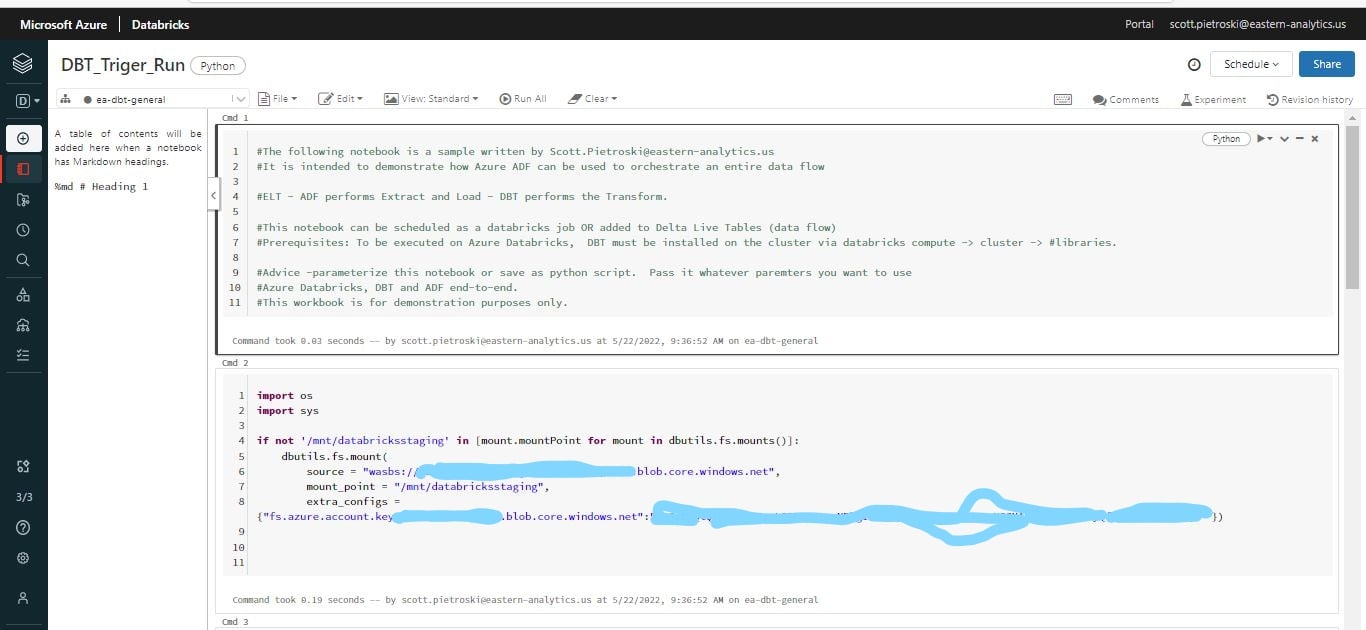
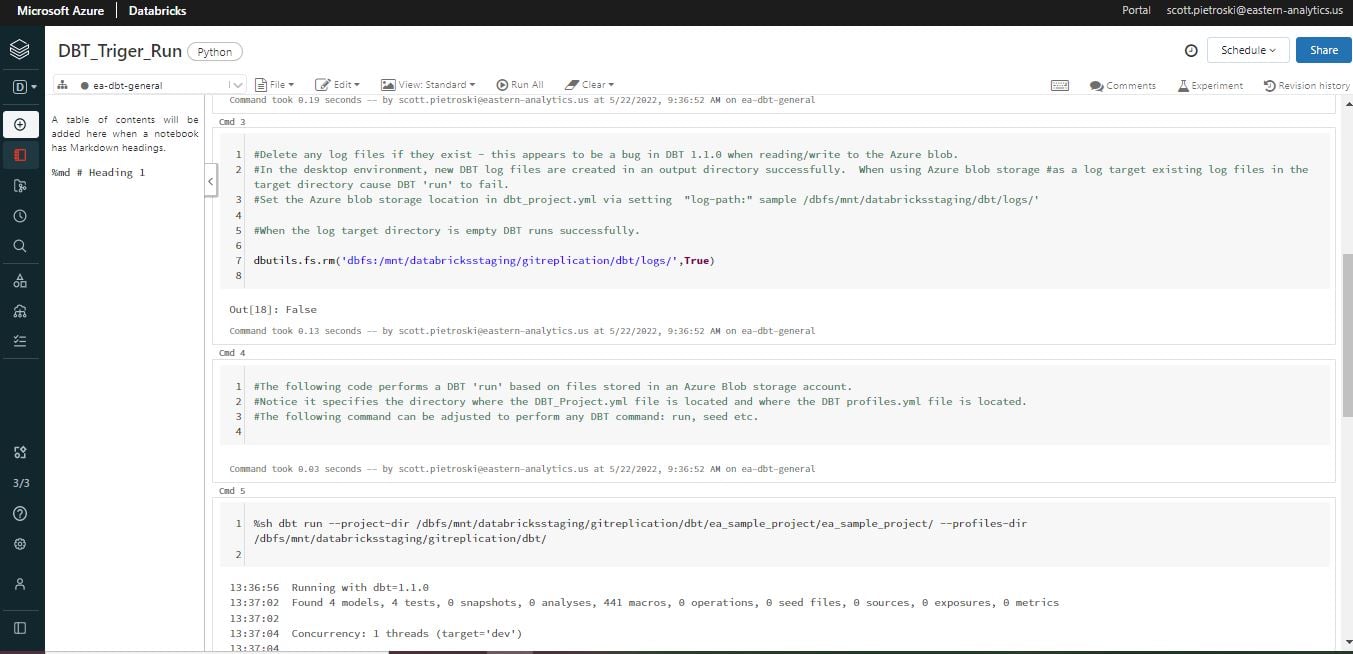
4) Upload a python notebook used to execute dbt commands. The following is a sample notebook created for this demo. It mounts to an Azure Blob Storage location and uses the dbt project files stored there while executing a dbt ‘run’ command. The notebook will need to be modified for production. Please see the comments in the notebook regarding a bug and workaround related to creating dbt log files on the Azure blob. Also, a sample command is included which will run specific dbt models/folders. This notebook can easily be parameterized to perform any dbt command on any part/portion of your dbt architecture.
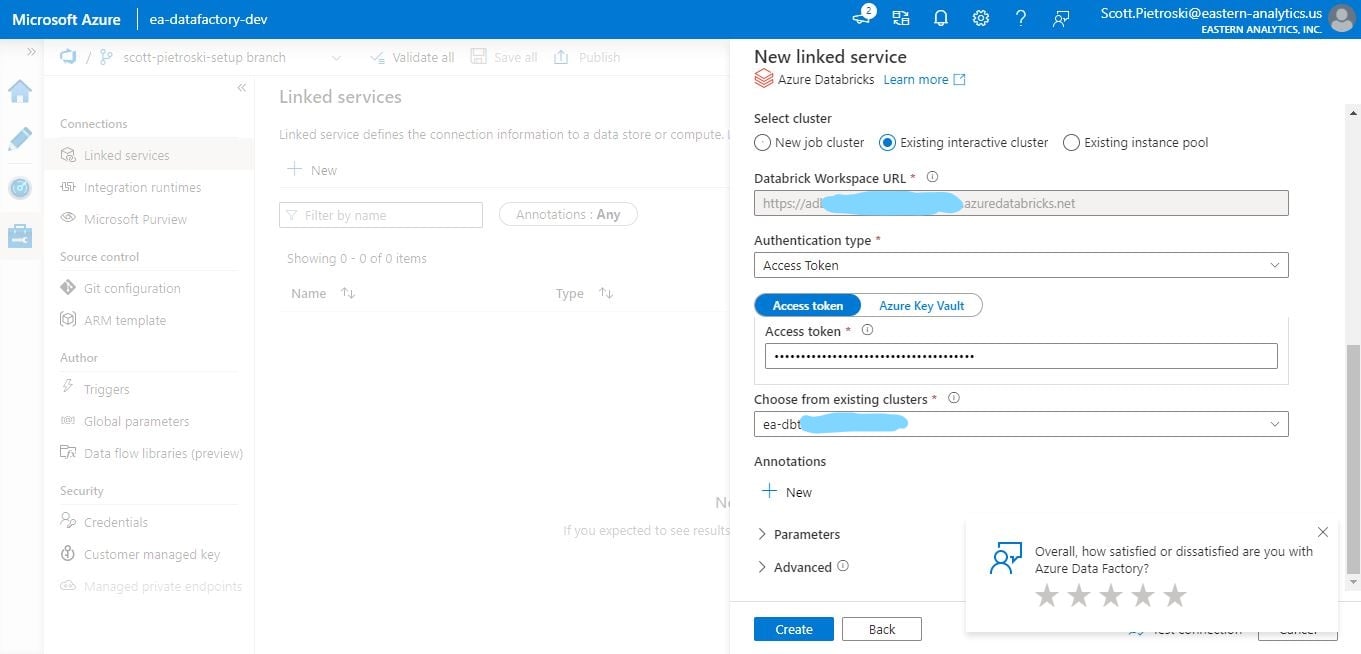
5) Create an ADF Linked Service to your Databricks compute. This may already be in place at your organization.
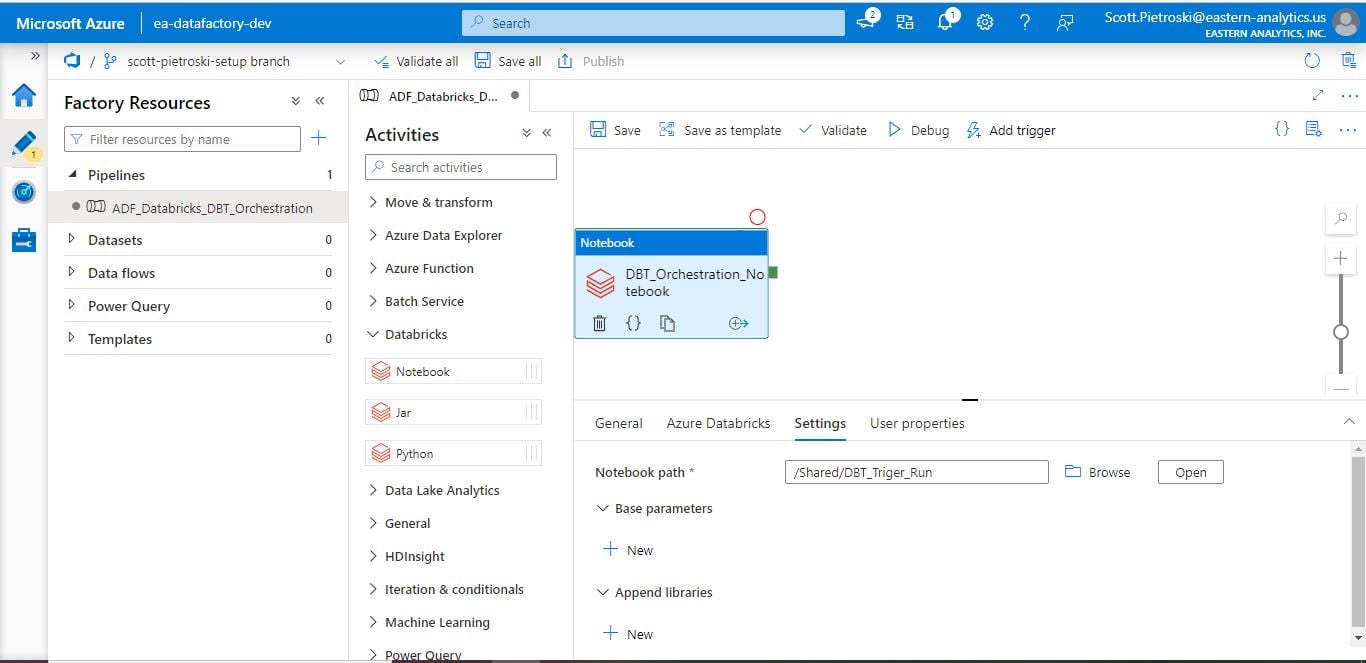
6) Create an ADF pipeline and add a Databricks notebook activity – pointing at the notebook uploaded in step 4.
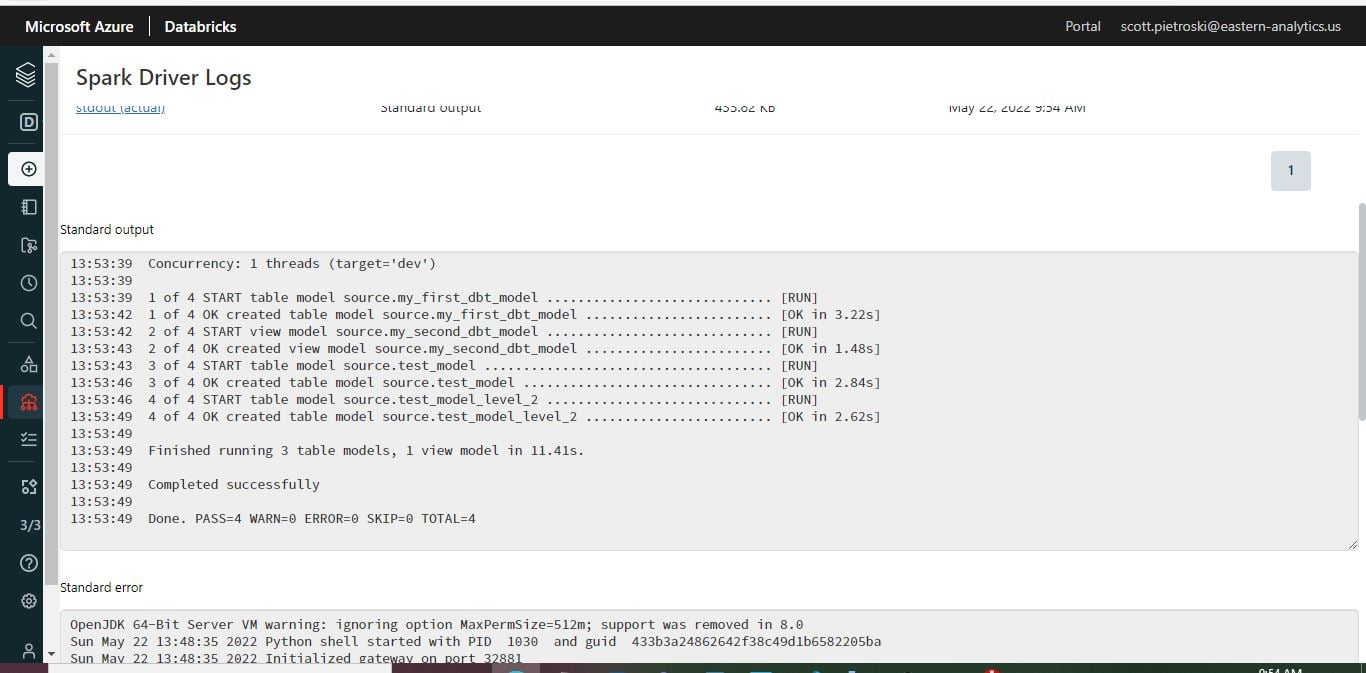
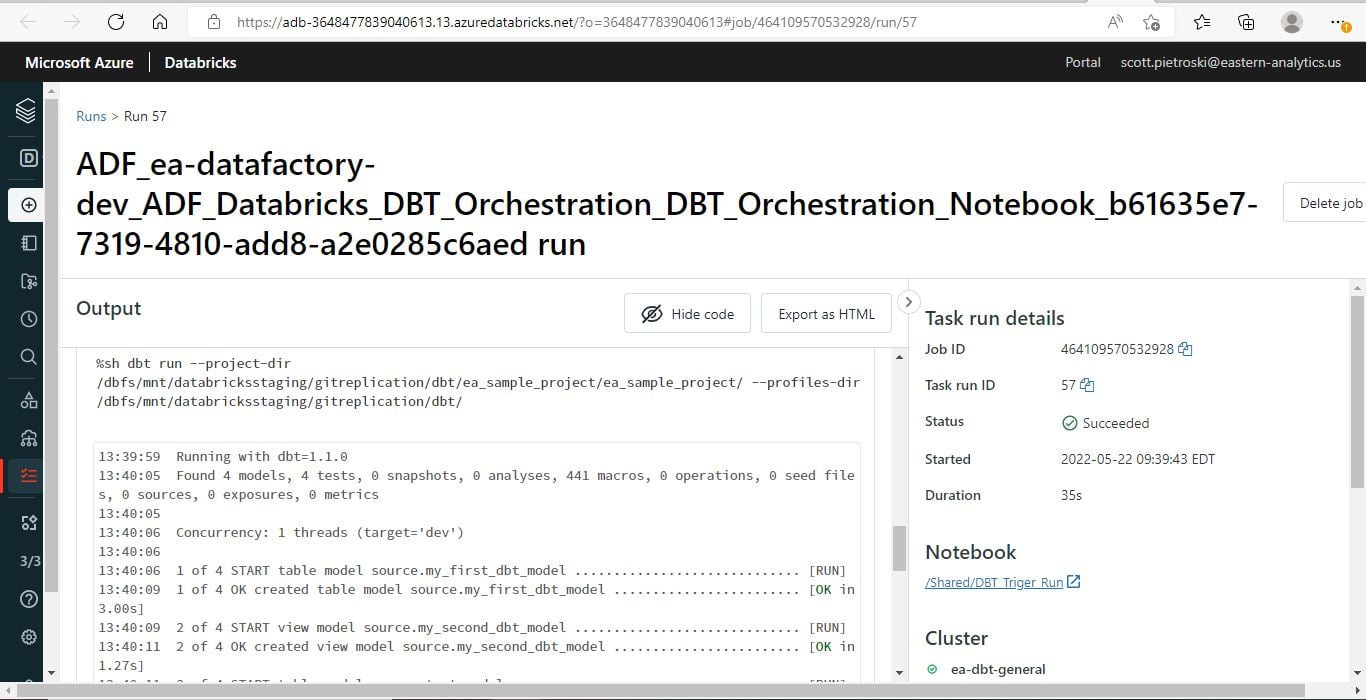
7) Execute your Azure ADF pipeline and view the results of the dbt run in the ADF Job Log!
8) Add a GitHub Action after your Master branch merge to keep your Azure Blob Storage dbt project files in sync. Example Command: curl -X PUT -T ./{file.dat} -H “x-ms-date: $(date -u)” -H “x-ms-blob-type: BlockBlob” “https://{storageaccount}.blob.core.windows.net/backups/{file.dat}?{sas-token}”
You can also schedule your notebook directly in Databricks or use it as a step in a Databricks Delta Live Table!
Conclusion:
Azure Data Factory (ADF) can be used to orchestrate your entire data flow. The solution is not out of the box, but with a little code it can:
Extract (“E”) data from almost any source
Load (“L”) data into your favorite data lake or Databricks Delta Tables
Transform (“T”) it using a variety of dbt commands
I hope you found this helpful.
Feel free to email me directly should you have any questions at scott.pietroski@eastern-analytics.us
Partner / Eastern Analytics, Inc. Solution Architect - Design thru delivery. 25+ Years of Data Warehousing, BI, Analytics, ML Specialties: MS Azure, HANA, Data Engineering, and Machine Learning experience.
Using parameters to pass information from outside a pipeline into a pipeline with ADF enables the pipeline to take on the properties of a function.
Scott Pietroski
Jan 2, 2020
Get notified on new marketing insights
Be the first to know about new B2B SaaS Marketing insights to build or refine your marketing function with the tools and knowledge of today’s industry.